Разбираюсь с машинным обучением. Моя промежуточная цель — создать искусственный интеллект для собственной онлайн-стратегии. Задача сложная, поэтому начинаю с малого. Читаю книгу «Обучение с подкреплением», автор Р. С. Саттон. Первая глава этой книги посвящена в том числе разбору примера игры в крестики-нолики. Поняв общую концепцию, мне захотелось реализовать её в коде, чтобы лучше разобраться в теме и поэкспериментировать.
Исходники
То, что у меня получилось, можно найти здесь:
https://github.com/alex-yashin/tictactoe-ai
Ниже я постараюсь объяснить, как решал задачу.
Простейшая модель обучения с подкреплением
Искусственный интеллект, играя в игру, должен выбрать ход из множества доступных в текущем состоянии игры ходов. Логично предположить, что компьютер будет выбирать самый выгодный для себя ход. Как определить выгодный ход или нет? Самый простой способ — попытаться оценить пользу от каждого хода и выбрать самый полезный. Очевидно, польза хода зависит от выгодности позиции в игре, которую получит игрок после этого хода. Поэтому имеет смысл перебрать все доступные ходы, оценить позиции, в которые ведет каждый ход, и выбрать ход, который ведет в лучшую позицию. Позицию в игре мы будем называть состоянием игры.
Остается найти способ, как правильно оценивать состояние игры. Можно было бы самому проанализировать правила игры и вывести некоторую формулу, по которой компьютер будет оценивать каждое состояние. Но это — не наш подход, мы хотим написать робота, который сам бы обучался игре, зная лишь её правила.
Компьютер должен сам каким-то образом оценивать состояние игры на основании своего опыта. Простейшая идея — задать у каждого состояния некоторую начальную оценку, которую потом корректировать, исходя из опыта игры.
Такую простейшую модель обучения с подкреплением можно выразить формулой:
V(s) = V(s) + α * [V(s’) - V(s)],где s — это текущее состояние игры, s’ - новое состояние игры, V — это ценность того или иного состояния, α — это некоторый коэффициент, который влияет на размер корректировки, и называется «размером шага».
Человеческим языком эта формула читается так: в ходе обучения необходимо корректировать ценность текущего состояния, учитывая последствия, которые наступили на следующем шаге. Если последующее состояние в ходе игры имеет большую ценность, чем ценность текущего состояния, то, возможно, текущее состояние недооценено и его ценность надо повысить. И наоборот, понижаем оценку текущего состояния, если оно привело к худшим последствиям. Размер шага используется для того, чтобы корректировка проходила плавнее, ведь если бы он был бы равен единице, мы просто переносили бы ценность последующего состояния на предыдущее, что было бы неверно, так как вариантов последующих состояний несколько, и каждое из них имеет свою собственную оценку.
Разработка игры
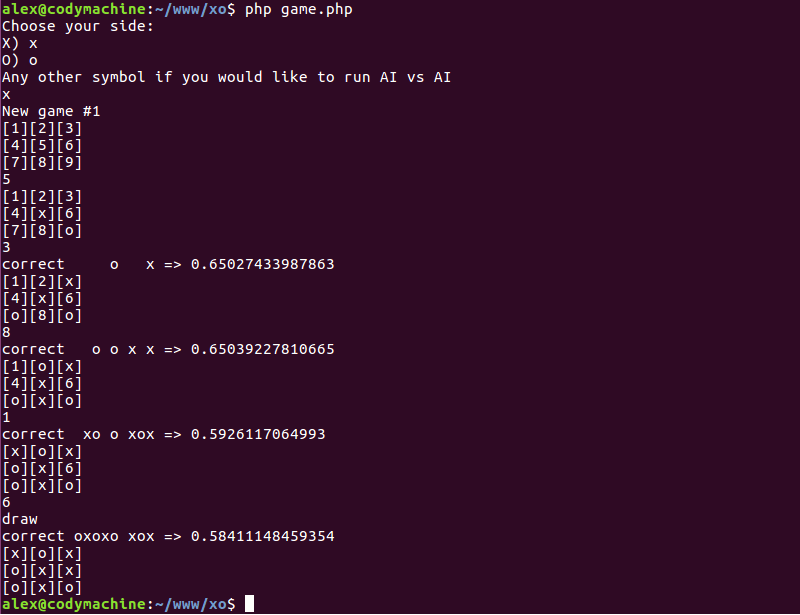
Вооружившись этой простой формулой, я взялся за программирование игры на простом скриптовом языке PHP. Игра — полностью консольная. Игровое поле я храню обычной строкой из 9 символов по одному символу на игровую клетку: символ «x» — крестик, символ «o» — нолик, символ пробела — пустая клетка. Выбор хода для игрока — это ввод номера клетки от 1 до 9, в которую он хочет сходить. Я реализовал вывод игрового поля в консоль, проверку выигрыша, получение списка свободных позиций, куда может сходить игрок. В первой версии, компьютер у меня просто выбирал случайным образом одну из свободных клеток, и ходил туда.
После этого я взялся за хранилище ценностей состояний. Я завел ассоциативный массив, в ключи положил состояние игры в виде строки из 9 символов, а в значения — оценку этого состояния. Так как между запусками скрипта прогресс обучения должен сохраняться, то при завершении работы я сохраняю табличку ценностей в файл rewards.json, а при старте — читаю её из файла.
Пока компьютер еще не начал обучение, то эта таблица пуста. Нам же необходимо уметь отдавать начальные ценности для всех позиций. Поэтому я написал метод, который для состояний выигрыша выдает ценность «1», для состояний проигрыша ценность «0», потом проверяет таблицу на наличие ценности для состояния, а если ее еще там нет, то считает ценность «0.5» (равноудаленную от выигрыша и проигрыша).
class AI
{
private $table = [];
//…
public function getReward($state)
{
$game = new Game($state);
//если победитель - мы, то оценка состояния игры "1"
if ($game->isWin($state, 'x')) {
return 1;
}
//если победиль - соперник, то оценка состояния игры "0"
if ($game->isWin($state, 'o')) {
return 0;
}
//смотрим ценность по таблице
if (isset($this->table[$state])) {
return $this->table[$state];
}
//если в таблице нет, то считаем начальной ценностью "0.5"
return 0.5;
}
//...
}Так как ценность состояния зависит от того, за кого играет компьютер, а хранить отдельные таблицы для крестиков и ноликов я не хотел, то в таблице состояний я всегда храню состояния, в которых компьютер играет за крестики. А если компьютер играет за нолики, то я заменяю нолики на крестики, а крестики на нолики.
Если компьютер будет строго ориентироваться на таблицу ценностей при выборе самого выгодного хода, то уже совсем скоро после небольшой корректировки весов у некоторых позиций, компьютер перестанет выбирать другие ходы, ведь у остальных позиций уже есть оценки «0.5» и они могут быть меньше оценок позиций, по которым компьютер уже получил скорректированные оценки. Поэтому необходимо часть ходов делать случайным образом, чтобы исследовать новые игровые ситуации. Эти ходы называются зондирующими. Я делаю зондирующие ходы с вероятностью 30%, хотя по мере обучения процент зондирующих ходов необходимо снижать, ведь они могут приводить компьютера к поражению, когда он уже научится выигрышным стратегиям.
class AIPlayer implements PlayerInterface
{
private $side = 'x';
private $ai = null;
private $oldState = null;
//...
public function makeStep(Game $game)
{
//получаем список доступных ходов
$free = $game->getFree();
//случайным образом решаем, является ли текущий ход
//зондирующим (случайным) или жадным (максимально выгодным)
if (($r = rand(0, 100)) < 30) {
//случайный ход
echo 'random step'."\n";
$step = $free[array_rand($free)];
$game->set($step, $this->side);
$this->oldState = $game->getState($this->side);
return;
}
//жадный ход
$rewards = [];
foreach ($free as $step) {
//для каждого доступного хода оцениваем состояние игры после него
$newGame = clone($game);
$newGame->set($step, $this->side);
$rewards[$step] = $this->ai->getReward($newGame->getState($this->side));
}
//выясняем, какое вознаграждение оказалось максимальным
$maxReward = 0;
foreach ($rewards as $step => $reward) {
if ($reward > $maxReward) {
$maxReward = $reward;
}
}
//находим все шаги с максимальным вознаграждением
$steps = [];
foreach ($rewards as $step => $reward) {
if ($maxReward > $reward - 0.01 && $maxReward < $reward + 0.01) {
$steps[] = $step;
}
}
//корректируем оценку прошлого состояния
//с учетом ценности нового состояния
if (isset($this->oldState)) {
$this->ai->correct($this->oldState, $maxReward);
}
//выбираем ход из ходов с максимальный вознаграждением
$step = $steps[array_rand($steps)];
$game->set($step, $this->side);
//сохраняем текущее состояние для того,
//чтобы откорректировать её ценность на следующем ходе
$this->oldState = $game->getState($this->side);
}
//...
}Корректировка согласно форумуле выше происходит в методе correct. Я использую коэффициент 0.1 для размера шага.
class AI
{
private $table = [];
//...
public function correct($state, $newReward)
{
$oldReward = $this->getReward($state);
$this->table[$state] = $oldReward + 0.1 * ($newReward - $oldReward);
echo 'correct ' . $state . ' => ' . $this->table[$state] . "\n";
}
//...
}Заключение
Чтобы запустить игру, перейдите в папку с игрой и напишите в консоли:
php game.phpИгра предложит вам выбрать сторону, за кого играть (за крестики или за нолики). Если вы никого не выберите, то игра будет играть сама с собой. Вы сможете выбрать количество игр, которое она сыграет таким образом, чтобы набраться опыта, а затем сыграть с ней, уже как с опытным соперником.
Я же в будущем попытаюсь расширить игровое поле до 10×10, вывести какие-нибудь численные оценки качества обучения, использовать при оценке позиций тот факт, что позиции могут быть симметричны, применить какие-нибудь методы улучшения процесса обучения компьютера.